计组试题
- Which type of memory will need refresh circuitry. A
A. DRAM B. Flash C. ROM D. Blu-ray
DRAM 除非被经常访问用于读/写,否则不能长期保持其状态 - The advantage of carry-lookahead adder is.D
A. decrease cost of the adder. B. save hardware parts.
C. augment CPU clock frequency. D. accelerate the generation of the carries.
carry-lookahead 就是为了减少加法器的延迟 - In the direct addressing mode.B
A. The operand is inside the instruction.
B. The address of the operand is inside the instruction.
C. The register containing the address of the operand is specified inside the instruction.
D. The location of the operand is implicit.
直接寻址模式(Direct Addressing Mode)是一种计算机体系结构中常用的寻址方式。在这种模式下,指令中直接包含要访问的内存地址。这种方式简单直接,访问速度快,但也有一定的局限性。下面详细介绍直接寻址模式的概念、特点和使用场景。
直接寻址模式的定义
在直接寻址模式中,指令中的地址字段直接指定了要访问的内存地址。处理器可以直接使用这个地址来读取或写入数据,而不需要进行任何额外的计算或转换。
指令格式
假设有一个简单的指令格式,其中地址字段直接指定了内存地址:
1 | | 操作码 | 地址 | |
- 操作码:指示处理器执行的操作,如加载、存储等。
- 地址:直接指定要访问的内存地址。
特点
- 简单直接:指令中的地址字段直接指定了内存地址,处理器可以直接使用这个地址进行访问,无需额外的计算。
- 访问速度快:由于地址已经明确给出,处理器可以直接访问内存,减少了寻址时间。
- 地址范围有限:地址字段的位数限制了可直接寻址的内存范围。例如,如果地址字段是 16 位,那么只能直接寻址 64KB 的内存空间。
使用场景
- 小规模系统:在小型嵌入式系统或早期计算机中,内存容量较小,直接寻址模式足以满足需求。
- 频繁访问固定地址:当程序需要频繁访问某些固定的内存地址时,直接寻址模式可以提高效率。
- 简单控制逻辑:在需要简单控制逻辑的场合,直接寻址模式可以简化指令集和处理器设计。
示例
假设有一个简单的指令集架构,其中有一条加载指令 LOAD,用于将内存中的数据加载到寄存器中。指令格式如下:
1 | LOAD R1, 1000 |
- R1:目标寄存器,数据将被加载到这个寄存器中。
- 1000:直接指定的内存地址。
处理器执行这条指令时,会直接访问内存地址 1000,将该地址中的数据加载到寄存器 R1 中。
与其他寻址模式的对比
- 间接寻址模式:指令中的地址字段指向一个内存位置,该位置存储了实际要访问的内存地址。
- 基址寻址模式:指令中的地址字段与一个基址寄存器的值相加,得到实际的内存地址。
- 相对寻址模式:指令中的地址字段相对于当前指令的地址进行偏移,得到实际的内存地址。
总结
直接寻址模式是一种简单高效的寻址方式,适用于内存容量较小或需要频繁访问固定地址的场景。尽管它的地址范围有限,但在许多嵌入式系统和简单控制系统中仍然非常有用。
- In a microprogram-control computer, the microinstructions are stored in a memory called the.D
A. direct memory B. physical memory C. virtual memory D. control store
5.5 控制信号
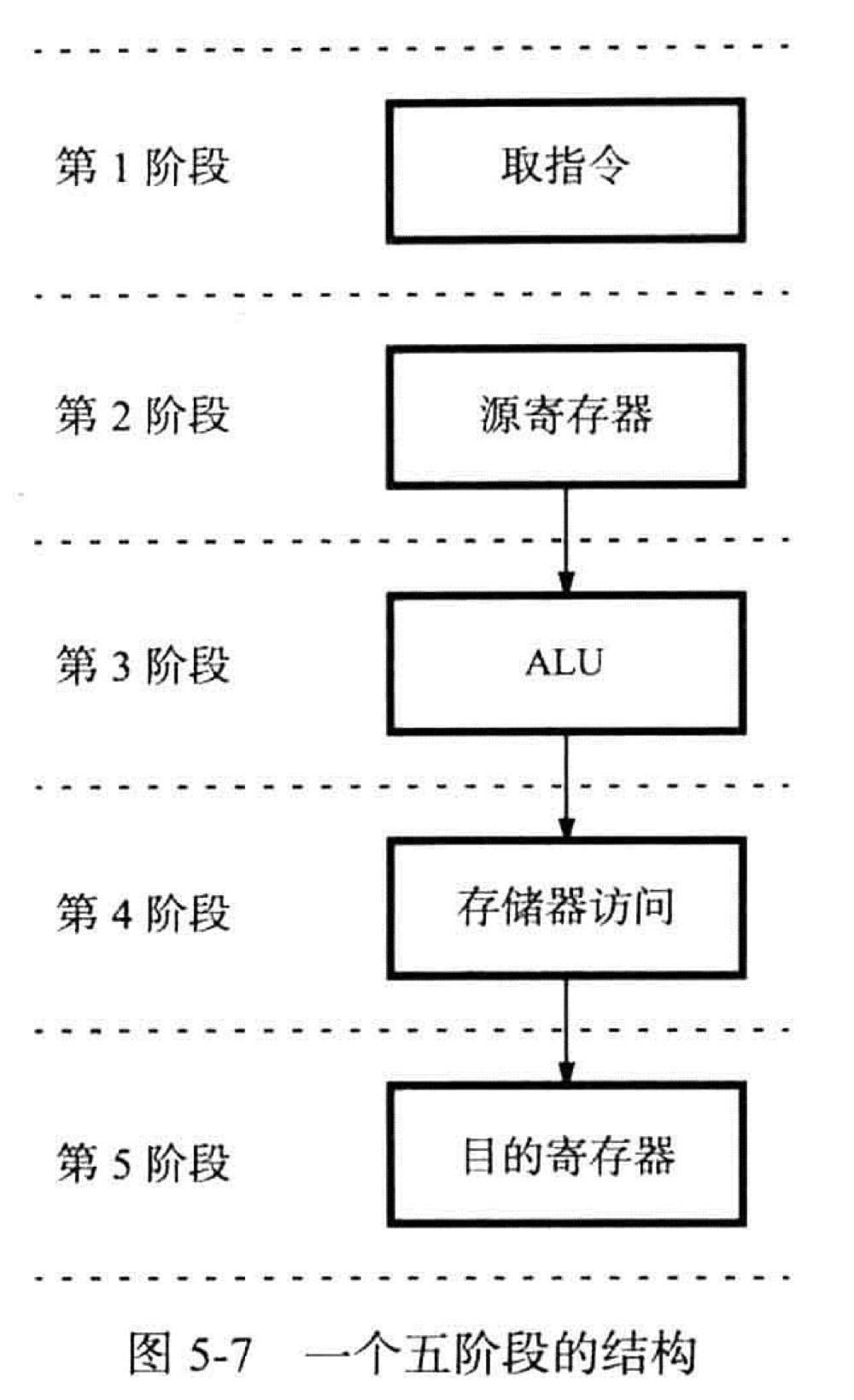
处理器硬件组件的操作是由控制信号控制的,这些信号决定多路复用器要选择哪一个输入端,ALU 要执行什么样的操作等
数据通路
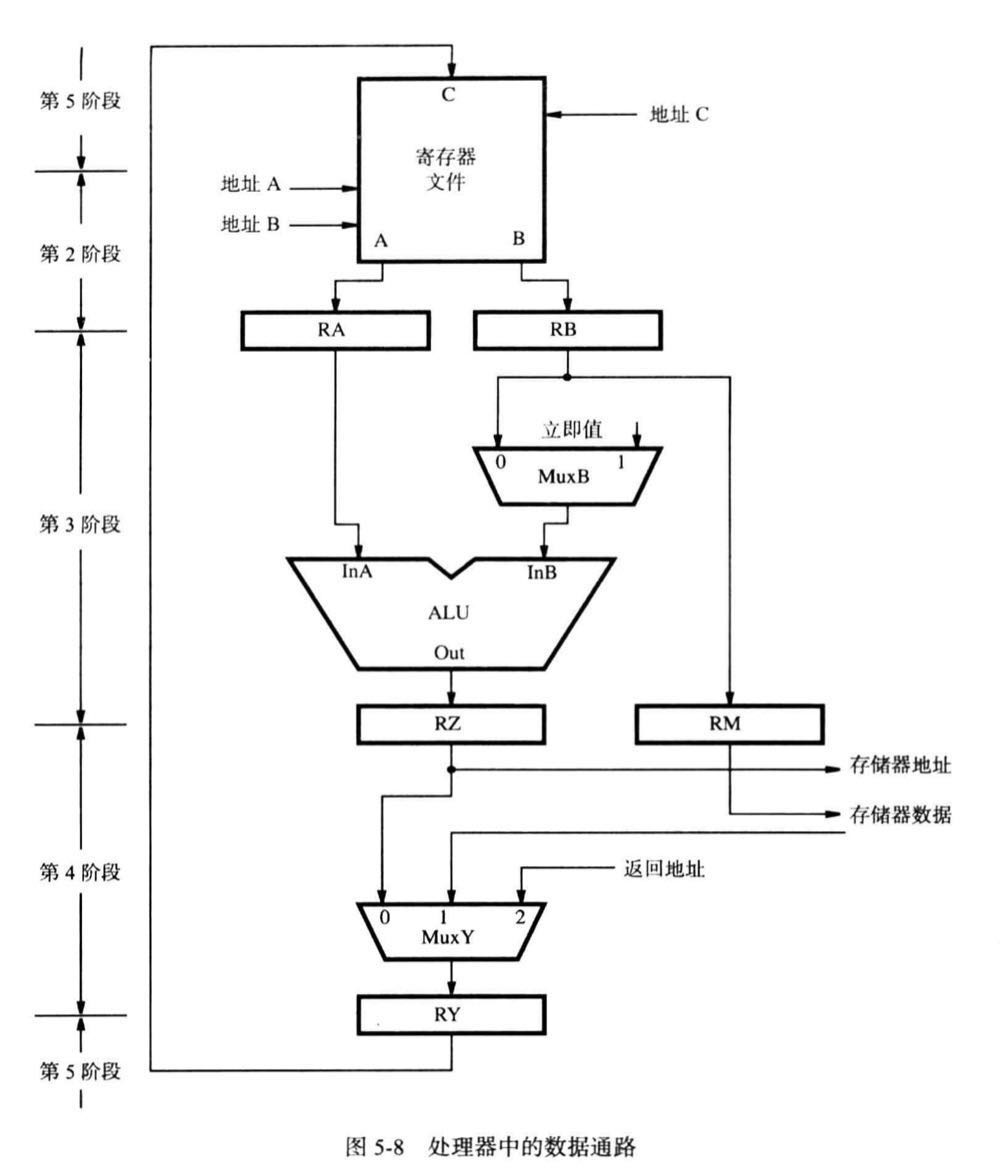
MuxB 选择寄存器 RB 中的内容或者是 IR 中的立即值
MuxY 端:
- 0 端口 如 add 命令第 4 阶段中没有处理动作,MuxY 选择 RZ 并且将计算结果传送给 RY,第 5 步中装入目的寄存器中
- 1 端口 对于 Load/Store 指令,ALU 在第三阶段计算出存储器操作数的有效地址并且装入 RZ。第 4 阶段该地址从 RZ 发送到存储器。对于 Load,MuxY 选择从存储器中读取的数据并且放入 RY,在第 5阶段传送给寄存器文件。对于 Store,数据在第 2 阶段从寄存器文件中被读出并且被放置到寄存器 RB中,RM 作为第 3,4 阶段的段间寄存器,在第 3阶段将 RB 中的内容传进 RM,在第 4 阶段将其存入存储器中,第 5 阶段无需采取任何动作
- 2 端口 子程序调用指令把返回地址保存在一个通用寄存器中,称为 LINK。与之类似,中断处理也要保存返回地址。可以通过 MuxY 的第三个输入端将返回地址传送至寄存器 RY 然后发送到寄存器文件中。
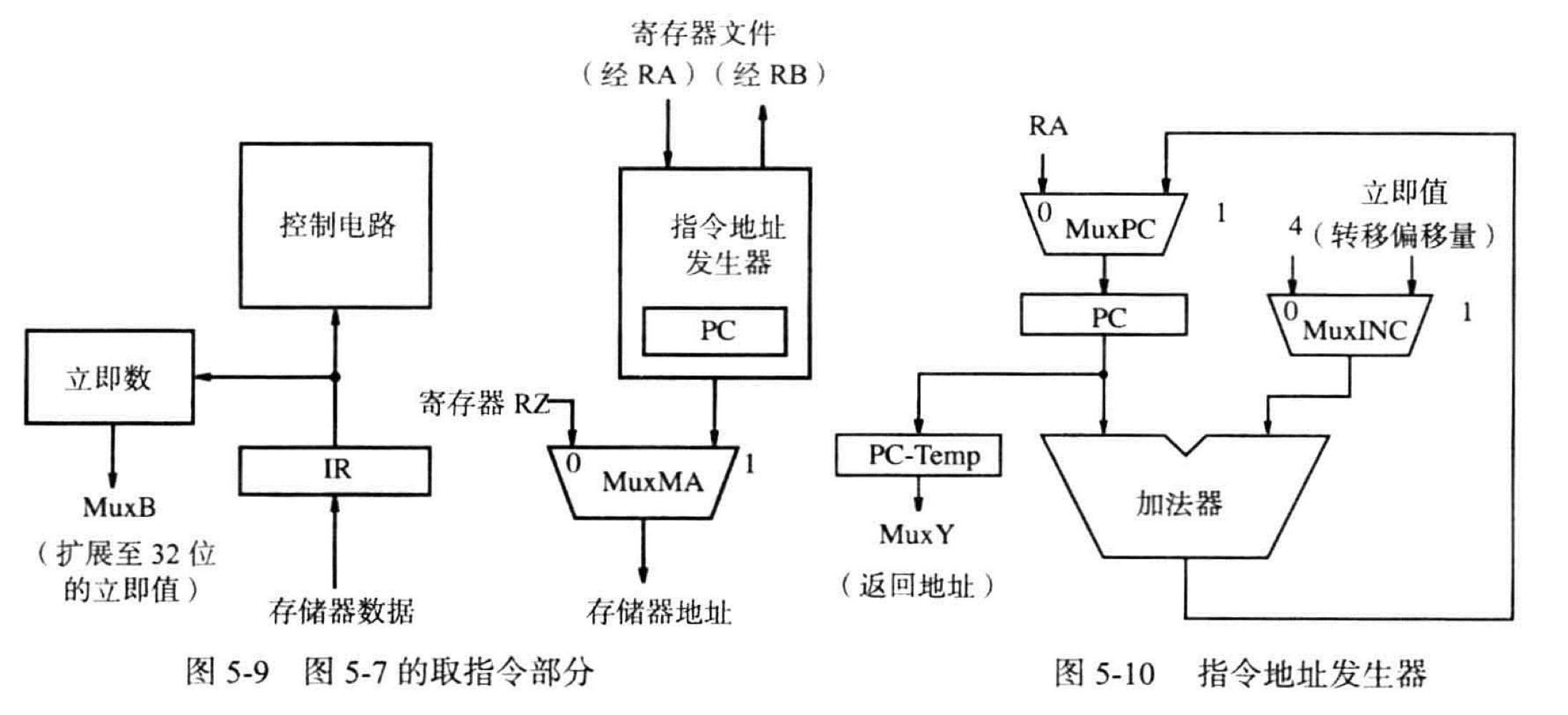
返回地址是由指令地址发生器产生的
取指令时访问存储器的地址来自于 PC,在访问指令操作数时访问存储器的地址来自于寄存器 RZ。MuxMA 会选择 PC 或者 RZ 中的一个并发送到“处理器-寄存器”接口。指令地址发生器回在取出每条指令后对 PC 的内容进行更新,从存储器中读取的指令会被存储进 IR 直到其执行完毕且下一条指令被取出。
控制电路可以检查 IR 的内容来生成控制处理器所有硬件所需的信号
立即数模块也需要用到 IR 的内容,并且需要进行扩展到 32 位 - 算术运算指令进行符号扩展
- 其他指令例如逻辑运算指令用 0 进行填充
立即数模块负责生成扩展值,可以用于ALU 计算也可用于计算转移指令的目标地址
地址发生器 - 在程序的线性执行中,加法器负责将 PC 递增 4
- 执行转移指令和子程序调用指令时,也可以用于计算一个将要被装入 PC 的新值
MuxINC 用于选择将常数 4 或者转移偏移量加到 PC 上。转移偏移量由立即数模块经过符号扩展之后给出。
MuxPC 在加法器的输出和寄存器 RA 的输出之间进行选择,LINK 用于在调用子程序或者中断的时候保存返回的地址,LINK寄存器的数据在第二阶段访问源寄存器的时候被放入RA
RA 一开始调用子程序的时候用于存放子程序开始的地址,PC 在第 3 阶段被装入 PC-Temp 之中,因为第 3 阶段无法直接写入寄存器文件,在第 5 阶段写入内置于控制电路中的寄存器 LINK 中。因为指令地址发生器中只有 RA 或者 4 可以连接到 MuxPC 然后被装入 PC 中,所以所有需要转移的指令都要先进入 RA,LINK 只是用于保存返回地址,但是最终还是需要放入 RA 才能实现转移
子程序返回命令将 LINK 中的内容放入 RA 中,再通过 MuxPC 放入 PC 中,中断指令除了使用不同的寄存器以外机制相同
寄存器 PC-Temp 用于临时存放 PC 的内容,并且通过 MuxY 传送给 RY 然后在第 5 阶段传输到寄存器文件中的 LINK 寄存器(通常)
数据在每个周期都从一个阶段传送到下一个阶段,所以段间寄存器总是处于启用状态,而其他寄存器 i.e.PC,IR 和寄存器文件在每个时钟周期内都保持不变,只有在特定的处理步骤中调用新的数据时才会启用
多路复用器的作用就是在任何阶段选择将要操作的数据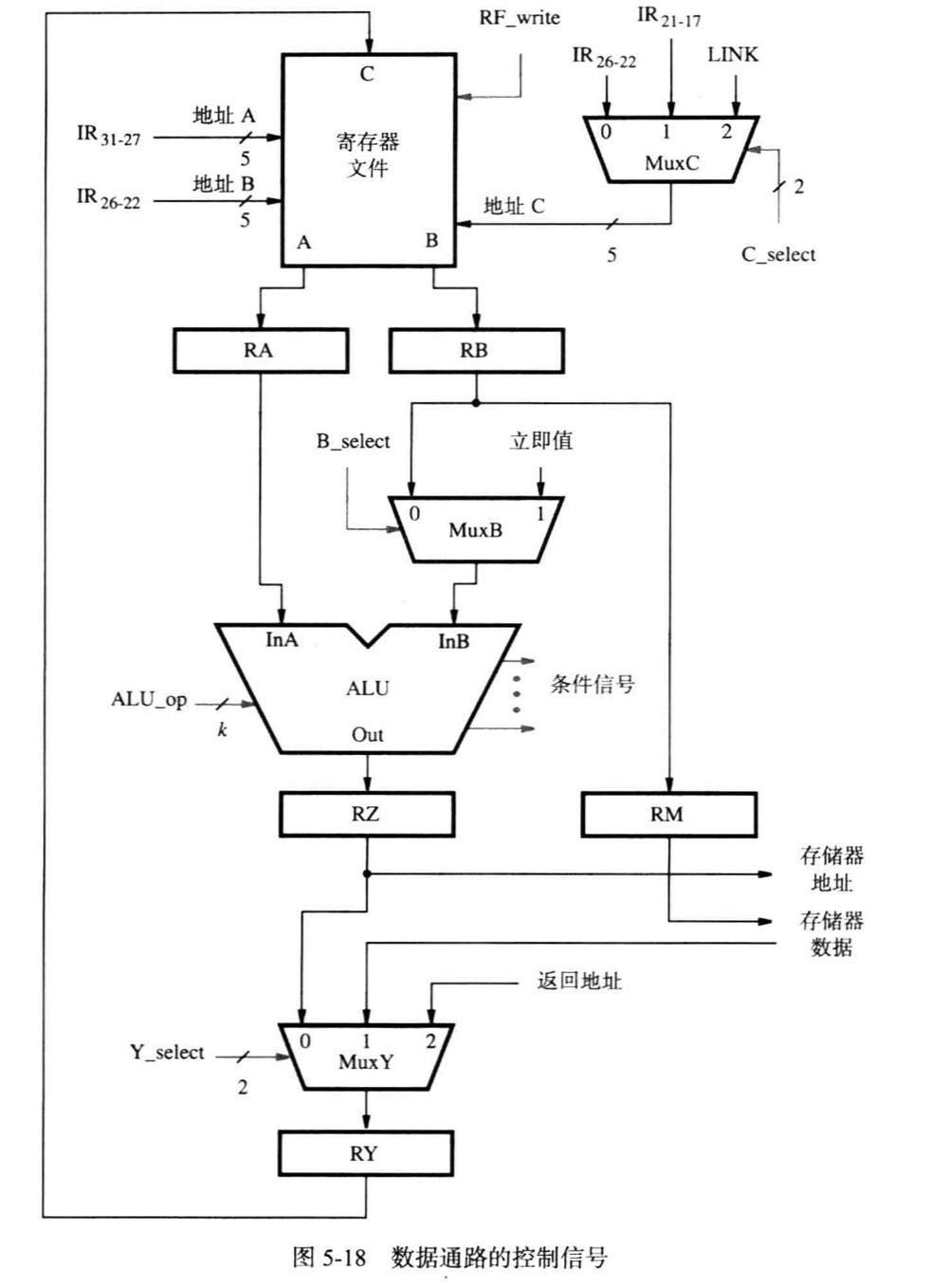
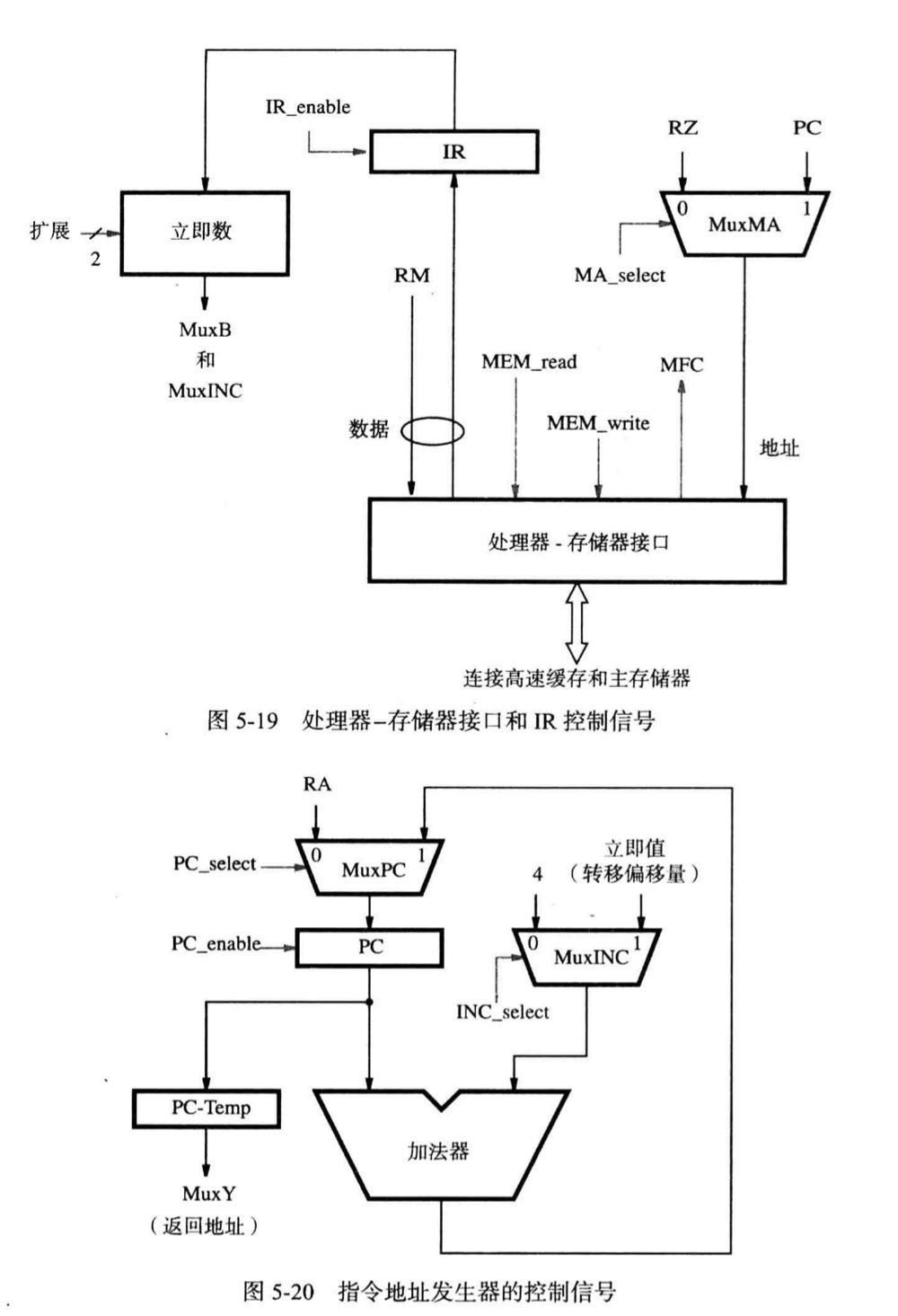
所需的控制信号如上图所示
寄存器文件有三个 5 位的地址输入端,可以访问 32 个通用寄存器,地址 A 和 B 用于确定将要读取的寄存器,与指令寄存器中的字段$IR_{31-27}和 IR_{26-22}$相连。第三个地址输入端地址 C 用于选择目的寄存器,端口 C 上的输入数据会被写入到该寄存器中新数据才会被装入所选择寄存器中
MuxC 和 MuxY 的控制信号需要两个位,因为需要从三个输入端中选择一个
MuxC 用于选择地址 C 的来源,三寄存器指令使用 $IR_{21-17}$而其他指令使用 $IR_{26-22}$来指定目的寄存器。MuxC 的第三个输入端是子程序链接指令中使用的链接寄存器的地址,只有控制信号RF_write 发出后数据才会被装入所选择的寄存器中
一个k 位的控制码 ALU_op 确定了 ALU 要执行的运算,可以表示 $2^k$个不同的运算,比较器会产生指示比较结果的条件信号,控制电路通过检查条件信号确定转移条件是否成立
MEM_read 和 MEM_write 两个信号用于初始化存储器读或写操作,请求的操作完成后处理器-存储器接口会发出 MFC 信号(存储器功能完成信号)。
IR 通过收到控制信号 IR_enable 将一条新的指令装入寄存器,取指令阶段中该信号必须在 MFC 信号发出后才能被激活
立即数模块需要处理三种可能的立即数形式:
- 16 位符号扩展值
- 16 位无符号扩展值
- 26 位以特殊方式处理的值
26 位的值右边填充 2 个 0,左边用 PC 的 4 个高位进行扩展用于子程序调用指令
5.6 硬件控制
处理器产生所需的 1 控制信号有两种方式:
- 硬件控制
- 微程序控制
指令按照一定的步骤序列进行执行,所以可以使用一个步计数器来跟踪执行的进度,在每一步内可以执行多个动作
控制信号的设置取决于: - 步计数器的内容
- 指令寄存器的内容
- 计算结果或比较操作的结果
- 外部输入信号,比如中断请求
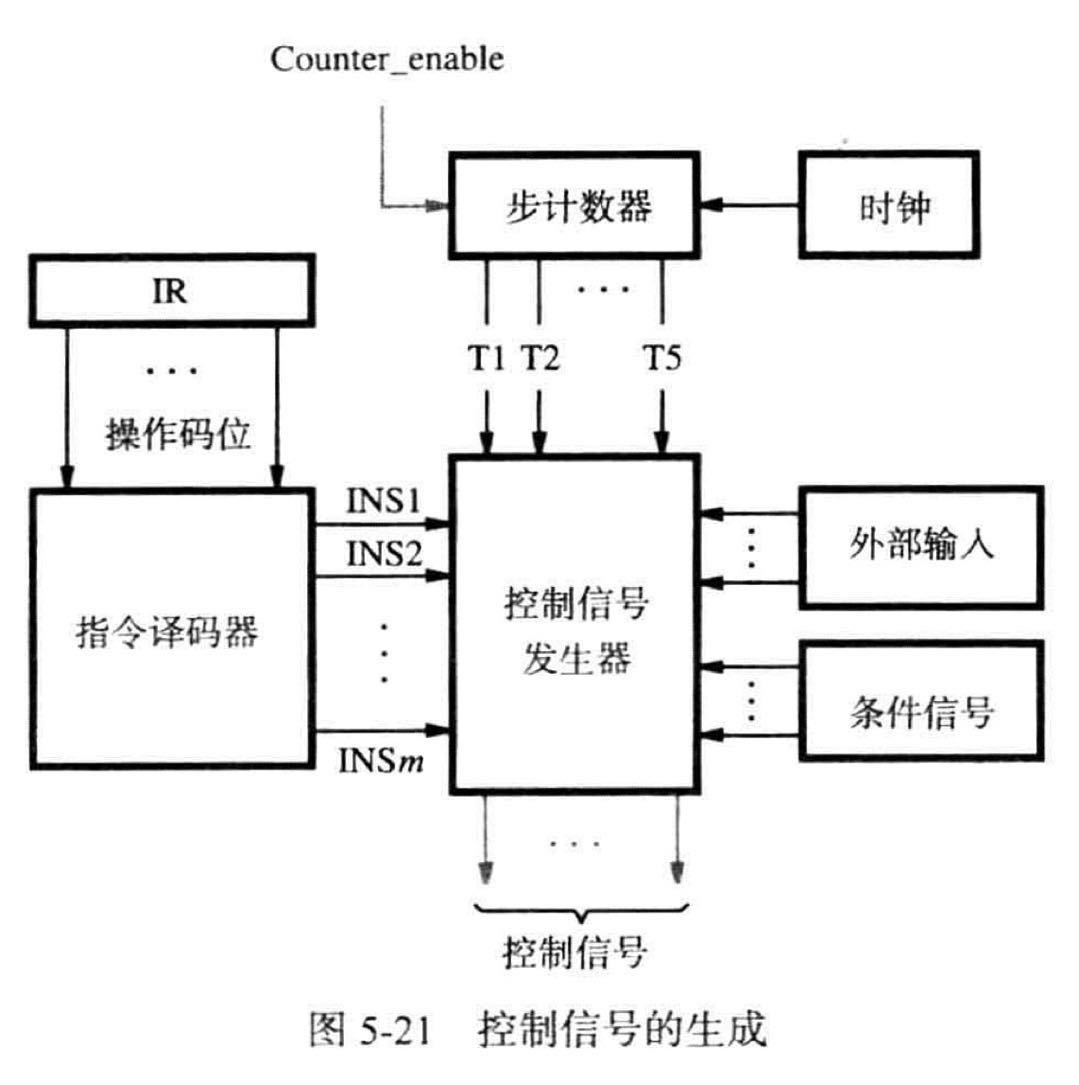
信号 INS1 到 INSm 表示实现每条指令所需要的动作序列
5.7.2 微程序控制
由存储在特殊存储器中的一个程序来决定每一步中控制信号所需的设置,把该控制程序称为微程序。
微程序存储在处理器芯片上一个小型而快速的存储器中,该存储器被称为微程序存储器或者control store(控制存储器)
控制字/微指令:用 n 位字中的每一位表示一个控制信号,其中每一位都制订了执行流中特定步的响应信号的设置。对于指令执行序列中的每一步都对应有一个控制字存储在微程序存储器(控制存储器)中
每个控制信号的值就是微指令中对应位的值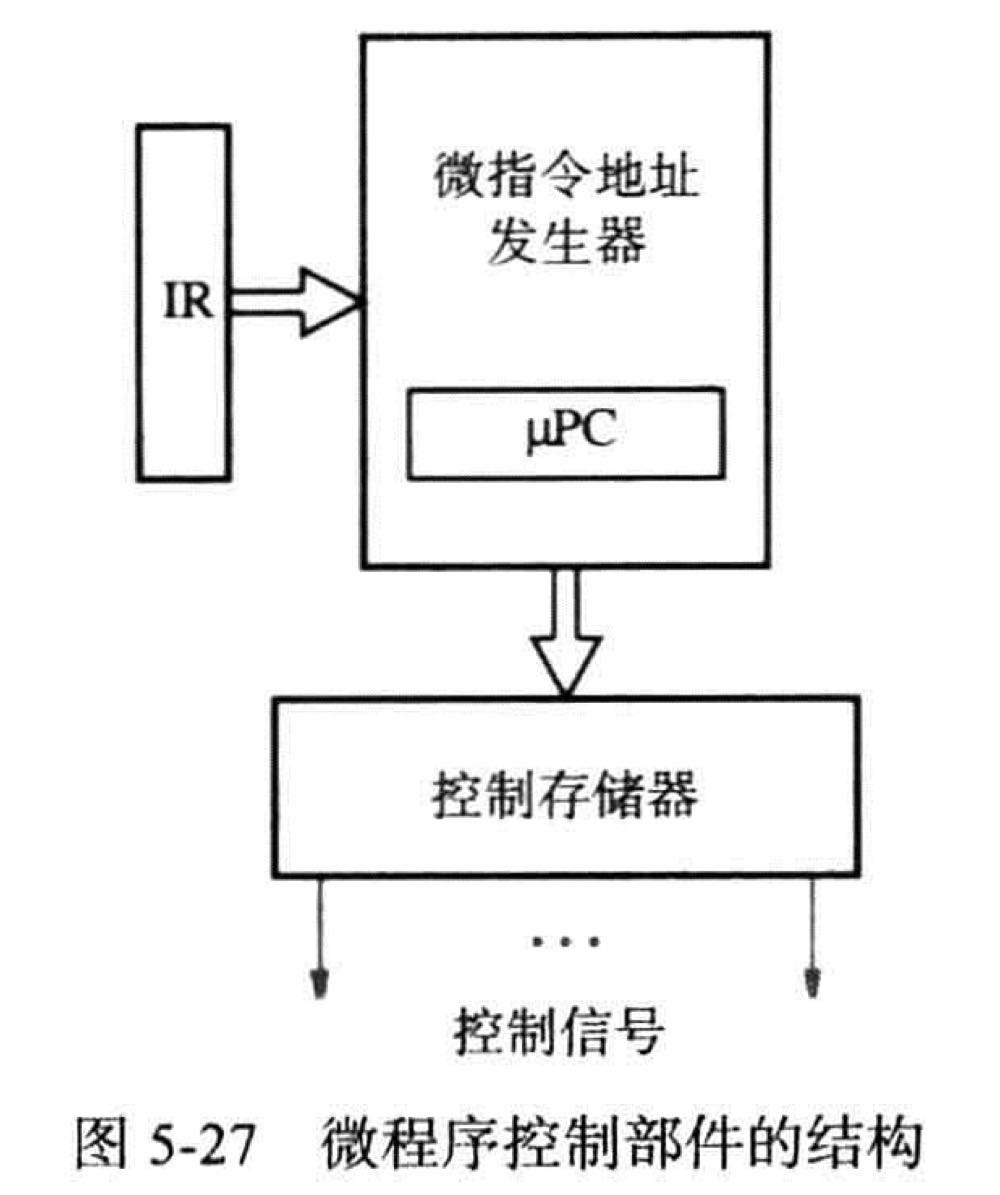 )
)
与给定机器指令相对应的微指令序列构成了实现该指令的微例程。前两部被固定为取指令和指令译码的操作,从第三步开始微例程才和给定的机器指令相对应
微指令地址发生器对 IR 中的指令进行译码,以便得到相应微例程的起始地址
微指令中有一个 End 位标记最后一条微指令,End=1 时地址发生器会返回到第一步对应的微指令,这样就可以取出一条新的机器指令
- Consider a four bit ALU which does four bit arithmetic. When computing 1101 + 1011, what is the status of NZCV flags.
NZCV flags
- N:negative,代表负数,如果结果是一个负数则这一位置为 1
- Z:zero,代表结果是否为 0,如果结果为 0 则置为 1,非 0则为 0
- C:
- 代表进位信号,如果$C_{n}$为 1 则置为 1,否则为 0
- V:overflow,代表溢出,如果计算结果发生了溢出则置为 1,否则置为 0
- The pipelining technique typically improves the performance of a computer by.C
A. decreasing the execution time of an instruction B. improving CPU block frequency
C. improving the throughput D. decreasing the cache miss rate
第六章 流水线
6.1 基本概念
五个阶段对应图 5-7:
- 取指令 Fetch
- 译码 Decode
- 计算 Compute
- 访存 Memory
- 写回 Write
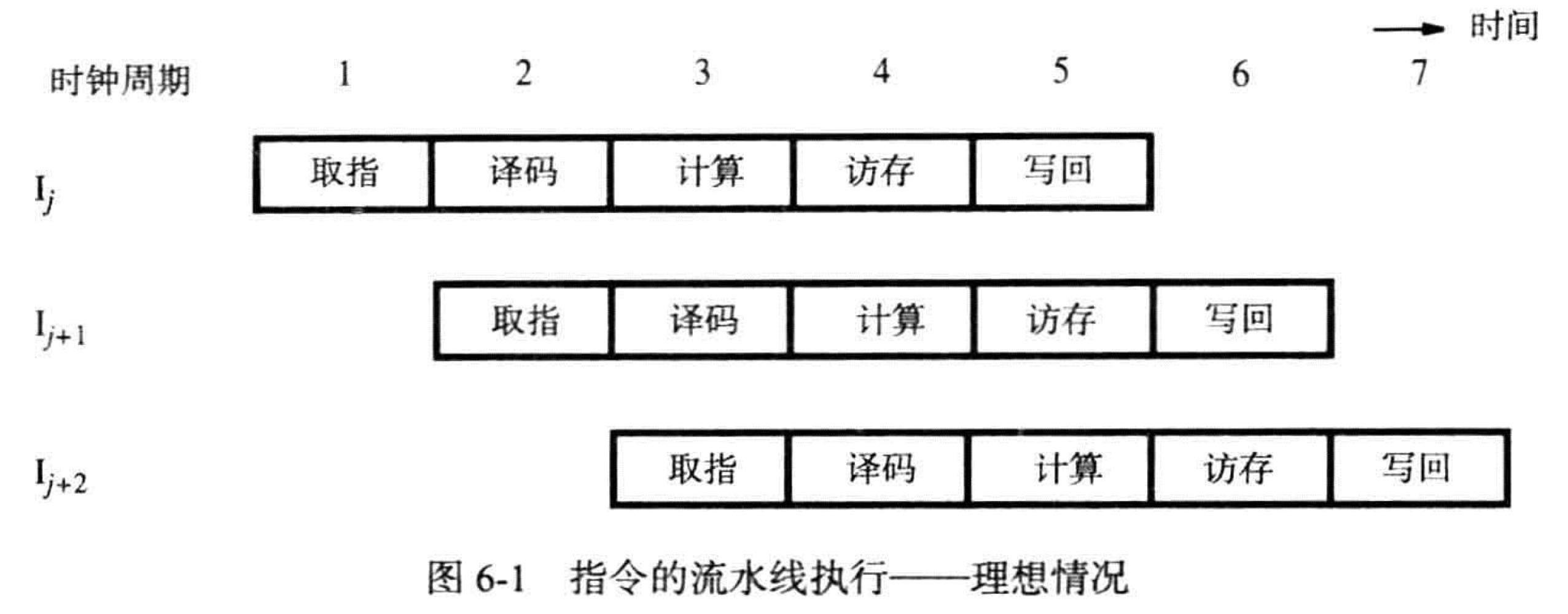
流水线是一种重叠执行的模式
任何一条指令仍需要五个周期才能完成,但是指令是按每个周期一条的速率完成的
6.2 流水线结构
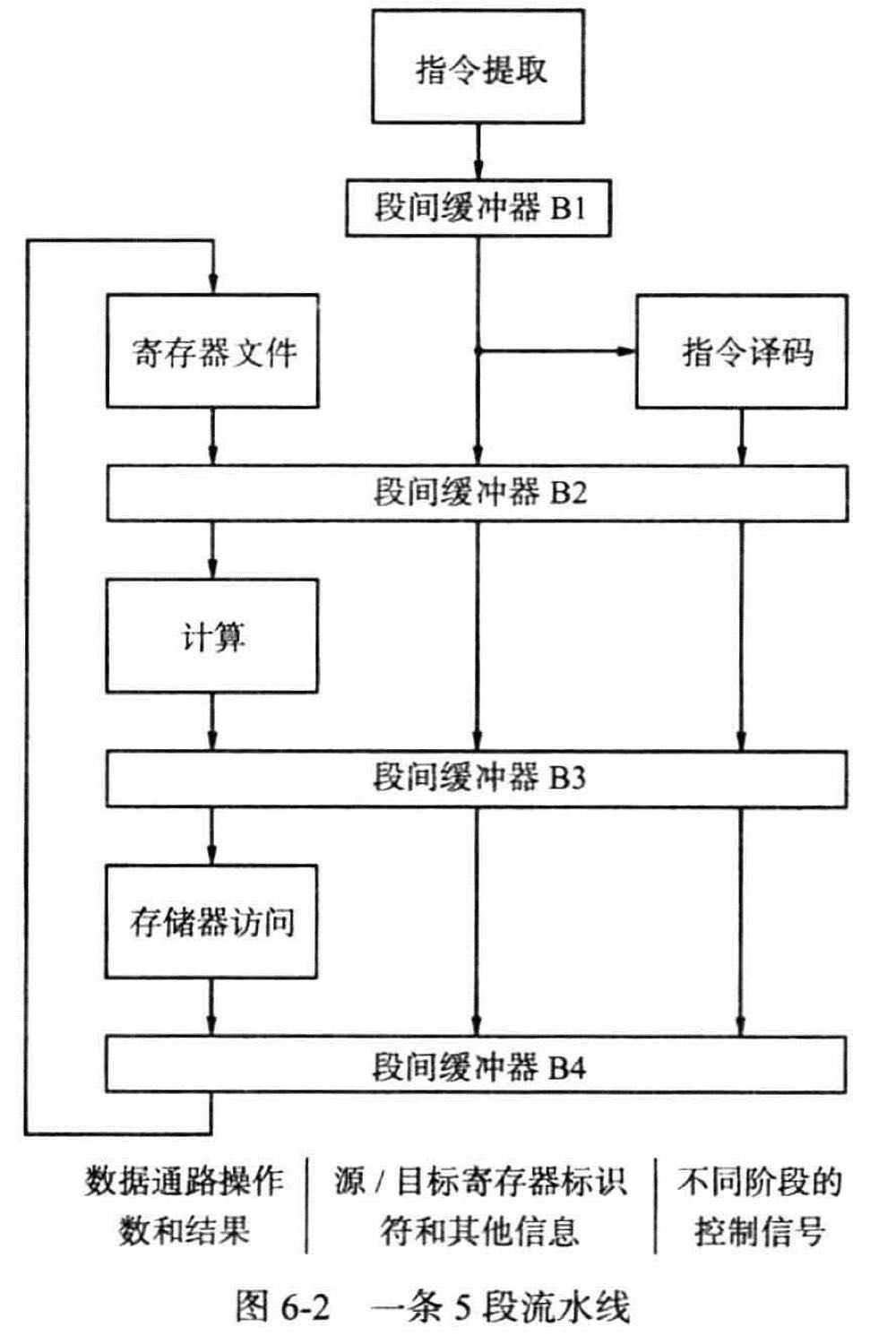
任何时间,流水线的每一个阶段都在处理不同的指令
随着每条指令进入下一个阶段,寄存器地址,立即数据和将要执行的操作之类的信息也必须背传送通过流水线,这些信息被保存在段间缓冲器中
- 段间缓冲器 B1 向译码阶段提供一条新提取的指令
- 段间缓冲器 B2 向计算阶段提供从寄存器文件中读取的两个操作数,源/目标寄存器标识符,来自指令的立即值,用作子程序调用返回地址的递增后的 PC 值,以及有指令译码器确定的控制信号的设置值
- 段间缓冲器 B3 保存 ALU 运算的结果,可能是即将写入寄存器文件的数据或者是送入访存阶段的一个地址。在 Store 时,B3 中保存要写入的数据,这些数据是在译码阶段从寄存器文件中读取的,存储在数据通路中的 RM 中。还保存从前一个阶段传递过来的递增后的 PC 值,以防需要它作为子程序调用指令的返回地址
- 段间缓冲器 B4 向写回阶段提供一个即将写入寄存器文件的值,可能是 ALU 的计算结果(第 3 阶段),也可能是存储器访问阶段(第 4 阶段)的结果,或者是作为返回地址写入 RA 的递增后的 PC 值
- The required control signals in a hardwired control unit are determined by the following information except. B
A. contents of the control step counter B. contents of the MAR (memory address register)
C. contents of the IR (instruction register) D. contents of the condition code flags
A 需要对每一步进行跟踪
C 是因为需要对于指令进行译码才能知道指令的具体内容,需要哪些控制信号
D 中的condition flags 即为条件码,就是 NCZV 等表示运算结果的条件位
运行时需要对这些信号进行检查才能知道接下来需要运行哪些指令,比如转移指令 - The processor informs the IO devices that it is ready to acknowledge interrupts by.B
A. enabling the interrupt request line B. activating the interrupt acknowledge line
C. activating the interrupt completion line D. enabling the interrupt starting line
3.2 中断
I/O 设备在准备就绪时主动向处理器发送 interrupt request 硬件信号来告知处理器其已经准备就绪
中断服务程序(interrupt-service routine):响应中断请求时执行的程序,也就是执行中断之后跳转去执行的程序(发出中断请求的程序)
发生中断时,当前 PC 的内容指向第 i+1 条指令,这个地址被称为 return address 必须被保存在一个指定的通用寄存器或者处理器堆栈中
处理器必须通知设备它的请求已经被识别,让该设备撤销其中断请求信号,该控制信号被称为interrupt acknowledge信号
interrupt latency:中断等待,从接收中断请求到开始执行中断服务程序之间的延迟,为了减少中断等待处理器通常只保存程序计数器和处理器状态寄存器的信息,剩下额外需要进行保存的内容都由显式的指令在中断服务程序开始时被保存,结束时被恢复
3.2.1 中断的允许和禁止
处理器中有一个状态寄存器(status register,PS),其中包含有关其当前操作状态的信息,该寄存器的一个位 IE 被分配用于允许/禁止中断
- IE=1 I/O 设备的中断请求被处理器接受并处理
- IE=0 处理器简单地忽略所有 I/O 设备的中断请求
I/O 设备的接口包括一个控制寄存器,其中包含可以管理设备操作模式的信息,该寄存器的一个位专门用于中断控制,只有该位设置为 1 的时候 I/O 设备才能被允许发出中断请求
3.2.2 处理多台设备
当收到一个中断请求时,需要识别是哪一台设备发出的中断请求。并且如果有两台设备同时发出中断请求,必须选择其中一个进行处理。执行完选中设备的中断服务程序后,处理器才可以响应第二个中断请求**
当设备发出中断请求之后。它的状态寄存器中的一位被置为 1 这一位称为 IRQ 位,
表示是否已经发出了中断请求且尚未被处理,使用轮询方式可以很简单的进行检查
- 向量中断:请求中断的设备可以直接向处理器标明他自己,然后处理器就可以可以立即开始执行相应的中断服务程序
在存储器中永久的分配一个区域用于保存中断服务程序的地址,这些地址被称为中断向量,而中断向量构成一个中断向量表
e.g. 分配 128 个字节用于保存一个包含 32 个中断向量的表 - 中断嵌套:I/O 设备以一定的优先级结构组织起来,在处理低优先级的设备的中断请求的时候,高优先级设备的中断请求应当被接受
对于某些设备,过长的中断请求过长的延迟会导致错误的操作
例如时钟的中断请求
为了实现这种方式,我们可以给处理器分配一个优先级,其只在程序的控制下改变。处理器的优先级就是当前正在执行成粗的优先级,处理器只接受优先级高于它的设备的中断。优先级可以编码在处理器状态寄存器的某一些位中。
如果允许嵌套的中断,那么每一个中断服务程序都需要把 PC 和 PS(状态寄存器)中的内容保存在堆栈中,在中断服务程序把 PS 中的 IE 设置为 1 以允许中断之前完成 - 同时请求:处理器必须决定哪个请求最先被服务
轮询显然
使用向量中断时使用硬件电路支持保证只有一台设备发送其中断向量代码
3.2.3 控制 I/O 设备行为
需要控制设备是狗允许中断处理器,这种控制在设备的接口电路中通常以**中断允许位(IE)**的形式提供
在设备接口中提供一个控制寄存器,其中包含控制设备行为所需的信息,数据寄存器/状态寄存器/控制寄存器都可以作为一个可被寻址的单元进行访问。寄存器中的一位作为中断允许位。
3.2.4 处理器控制寄存器
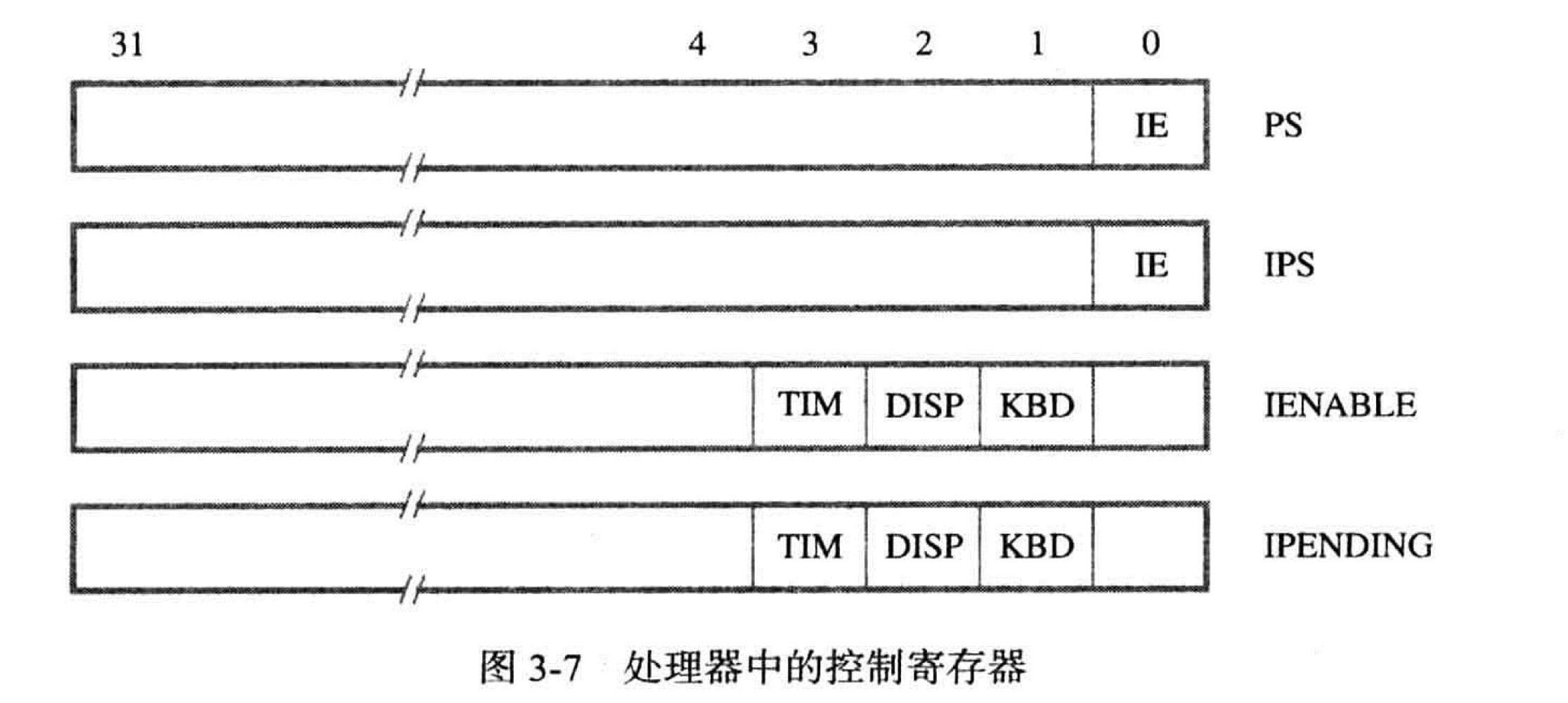
当收到一个中断请求并且接收其请求时,IPS 寄存器会自动保存 PS 寄存器的内容,在结束时也会传输回 PS 使其恢复以前状态,在中断嵌套中很重要
IENABLE 寄存器可以使处理器有选择的响应每个 I/O 设备
可以在 IENABLE 寄存器中为每个设备分配一位,当某位被置为 1 时处理器将接受所对应设备的中断请求。IPENDING 寄存器指示活跃的中断情求,当多个设备同时发出请求时将方便哪个中断应当首先被服务。
对于状态寄存器的内容有专门的指令MoveControl IENABLE,R3
将 R3的内容放入 IENABLE 寄存器中,完成控制寄存器与通用寄存器之间的数据传输操作
- The starting address sent by the device in vectored interrupt is called as.A
A. interrupt vector B. location ID C. service location D. service ID - If the bytes 0x12, followed by 0x34, followed by 0x56, followed by 0x78 are interpreted as a 4-byte little endian integer, what value will they have.
0x78563412 - Explain the process of DMA.
DMA(Direct Memory Access)
首先由处理器执行的程序初始化一个字块的传输,向 DMA 控制器发送起始地址,块内字数,传输方向等必要的信息,然后由 DMA 控制器对每一个传输的字提供存储器地址,产生需要的所有控制信号,为连续的字增加存储器地址并且累计已传输的字数。最后当整块数据传输完成之后 DMA 控制器产生一个中断信号通知处理器传输已经全部完成。
8.4 直接存储器访问
直接在主存和 I/O 设备之间传输数据块
控制 DMA 传输的部件称为 DMA 控制器,访问主存时 DMA 控制器执行本来由处理器执行的功能。对每一个传输的字提供存储器地址,产生需要的所有控制信号,为连续的字增加存储器地址并且累计已传输的字数
DMA 的操作必须由处理器执行的程序控制,该程序一般是一个操作系统例程。
为了初始化一个字块的传输,处理器需要向 DMA 控制器发送起始地址,块内字数以及传输方向等信息。然后 DMA 控制器就开始执行所请求的操作。当整块数据传输完成之后其产生一个中断信号通知处理器。
- Imagine a system with the following parameters. Virtual addresses 20 bits, physical addresses 18 bits, page size 1 KB. Please give the format of virtual address and physical address. Explain your answer.
1KB=$2^{10}$Byte 所以需要 10 位作为偏移量
虚拟地址中剩下 10 位作为虚拟页号
物理地址中剩下 8 位作为页帧 - The two numbers given below are multiplied using the Booth’s algorithm. Multiplicand: 0101101011101110. Multiplier: 0111011110111101. How many additions/subtractions are required for the multiplication of the above two numbers.
01110111101111010
显然为 8 次 - In a computer, can we build a memory system with one type of memory to get a large, fast and cheap memory.
不能,根据硬件原理,存储容量较大且造价低廉的存储器必然访问时间就更长,访问时间很短的存储器造价普遍很昂贵,存储容量相对较小。所以不能~。更好的方式是构建存储器的层次结构,这样对于计算机来说就好像是拥有了一个访问相对快速并且容量较大造价也较为适中的存储器。 - Suppose we have a 7-bit computer that uses IEEE floating-point arithmetic where a floating point number has 1 sign bit, 3 exponent bits, and 3 fraction bits. The exponent part uses an excess-3 representation. The remaining 3-bit mantissa is normalized with an implied 1 to the left of the binary point. Rounding is employed as the truncation methal.
(1) Write the largest positive normalized floating-point number. And write the smallest positive normalized floating-point number.
(2) Write the result and computation process of A+B. Give the result in normalized form. A = 1.001, B= 0.010111.
(1)0 111 111=1.111*$2^{7-3}$=1.111*$2^{4}$=11110=30
0 000 000=1.000*$2^{0-3}$=0.125
(2)1.011111 运用 rounding 的截取方式得到 1.100
0 011 100 - Is it possible to design an expanding opcode to allow the following to be encoded in a 12-bit instruction. Justify your answer. Assume a register operand requires 3 bits and this instruction set does not allow memory addresses to be directly used in an instruction.
(1) 6 instructions with 3 registers
三个寄存器需要 3*3=9bit ,剩下 3bit 可以表示$2^{3}>6$条指令
即开头为 000-101 是 3 寄存器命令
110 和 111 为高 3 位的不是 3 寄存器命令
(2) 14 instructions with 2 registers
高三位均为 110 或 111
两个寄存器需要 6bit,剩下 6bit-3bit=3bit
这 3bit 还有 3 操作数指令剩下的 2 种有$2^{3}*2=16$种 可能>14,又剩下两位用作下一种指令
110000-110111 都是 2 寄存器命令,111000-111101 是 2 寄存器命令
111110 和 111111 用于小于 2 寄存器的命令
(3) 15 instructions with 1 register
111110000-111110111 都是 1 寄存器命令,111111000-111111110 都是 1 寄存器命令
剩下 111111111 是 0 寄存器命令
又用掉 15 条指令,剩下$2^{3}*2-15=1$种用于表示无寄存器的命令
(4) 8 instructions with 0 register
都以 111111111 开头 111111111000-111111111111 一共 8 种
有$2^{3}=8$种可能,刚好放得下
所以综上所述,足够表示 - Part of a RISC-style processor’s datapath is shown as the following figure. Instruction execution can be divided into 5-stages. Now we want to execute Mutiply R7, R8, R9 on this datapath. Before this instruction, [R7]=20, [R8]=10, [R9]=30. Write the values of registers at the end of instruction stage 2, stage 3, stage 4. 2.[RA],[RB]. 3.[RZ]. 4.[RY].
第二阶段是译码并且从寄存器文件中读取寄存器内容的阶段
[RA]=10,[RB]=30
第三阶段是 ALU 进行运算的阶段
[RZ]=30*10=300
第四阶段是进行存储器操作的阶段
[RY]=300 - The following sequence of RISC instructions are executed on a 5-stage pipeline. We can indicate the 5 stages of the pipeline using: F, D, C, M and W. Add R2, R1, R3. Sub R4, R2, R1 And R5, R1, R2 Sub R6, R2, R4
(1) Write all the data dependencies in the four instructions above.
sub 命令的源寄存器是 add 命令的目标寄存器,依赖于 add 命令
and 命令也同样依赖于 add 命令
第二个sub 命令既依赖于 add 命令也依赖于第一个 sub 命令
(2) Draw a figure to illustrate the execution of the four instructions on the pipeline. Assume that the pipeline has operand forwarding paths. Pay attention to mark the forwarding paths.
6.4 数据依赖性
6.4.1 操作数转发
数据依赖性:一条指令的目标寄存器刚好是另一条指令的源操作数
但是实际上指令并不需要等到上一条指令完成后再开始执行,所需的值有可能在第三个周期的末尾 ALU 已经完成 Add 指令操作之后就可以使用了
这个值被装入寄存器 RZ 中,寄存器 RZ 是段间缓冲器 B3 的一部份,硬件可以将这个值转发至第 4 个周期中需要它的地方–ALU 的输入端而不必延迟下一条指令
e.g.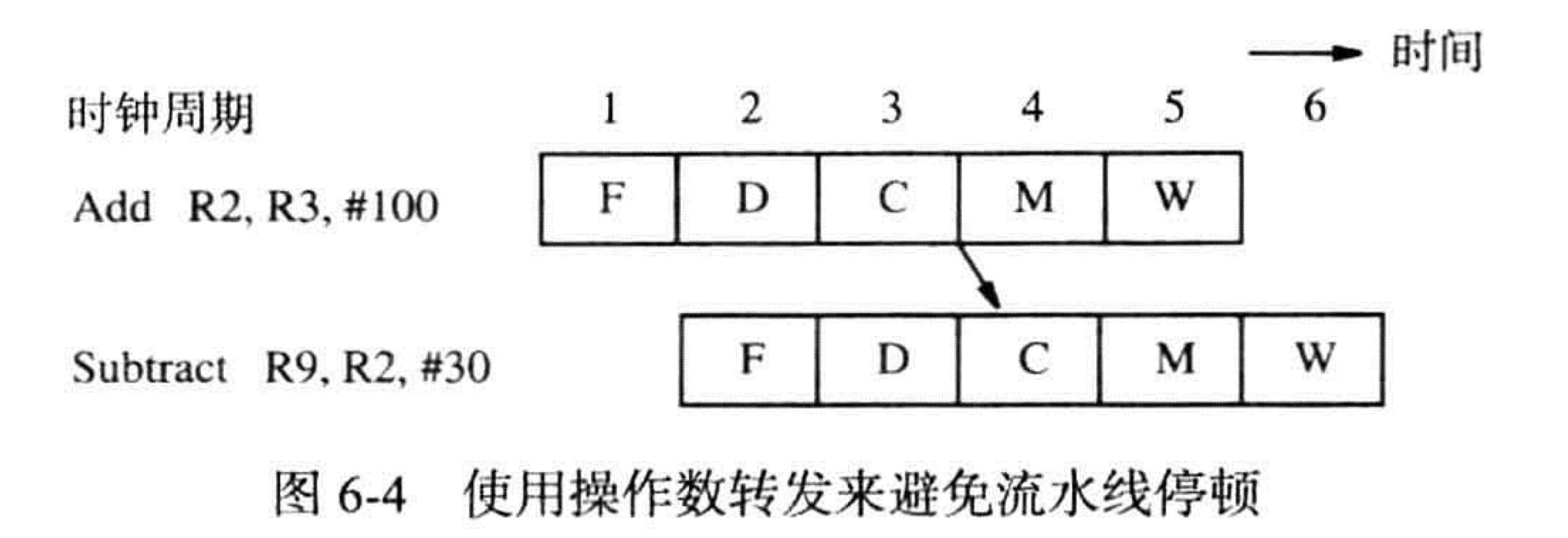
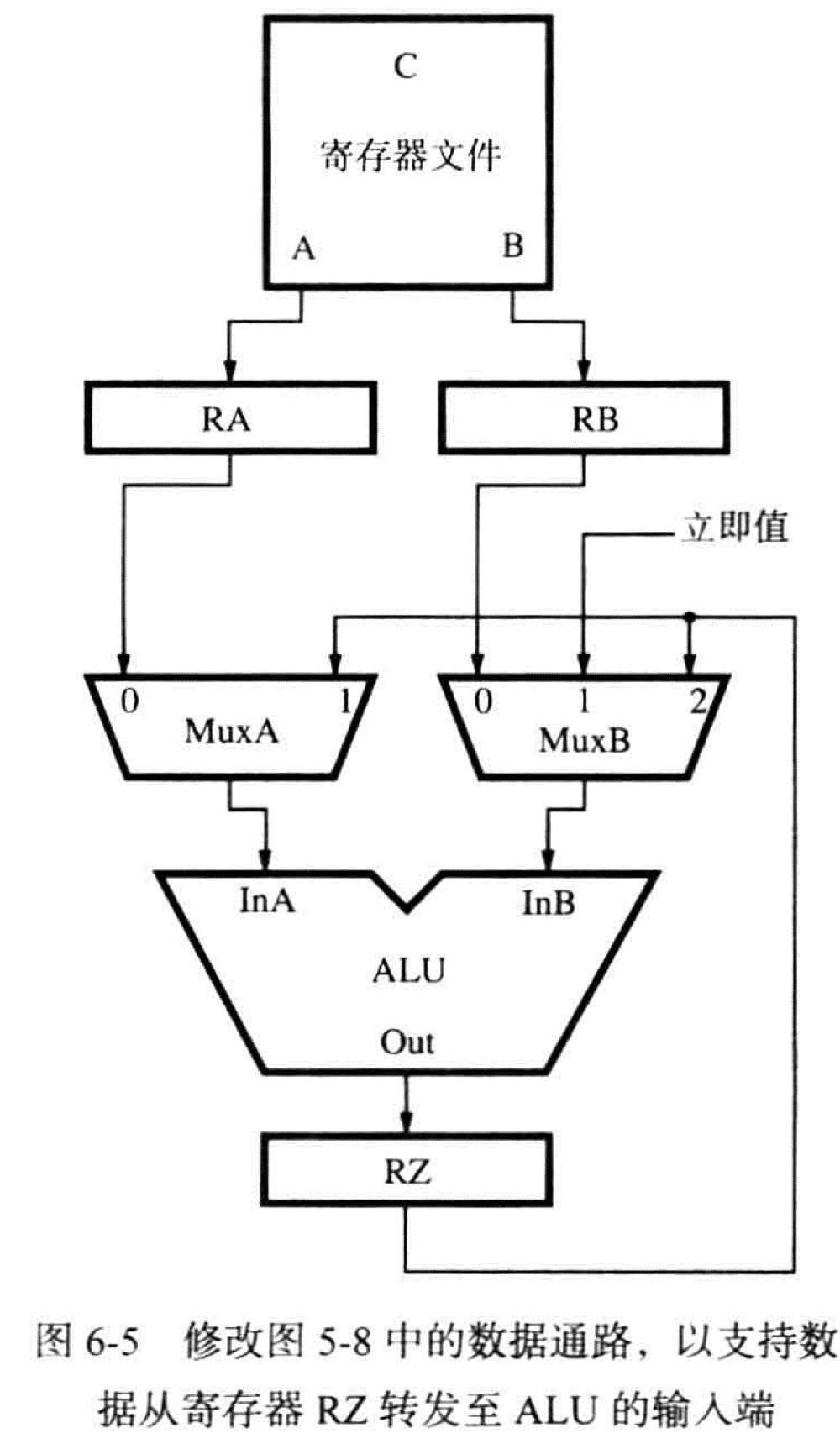
6.4.2 用软件处理数据依赖性
让编译器检测和处理数据依赖性,在两条具有数据依赖性的指令之间插入显式的 NOP 空操作指令从而引入必要的延迟
为了减少延迟,编译器可以尝试优化代码,通过重新排序指令将有用的指令移到 NOP 槽中减少代码长度,但必须考虑到数据的依赖性
- An integrated circuit RAM chip can hold 2048 words os 8 bits each (2k8).
(1) How many addresses and the data lines are there in the chips.
11,8
(2) How many chips are needed to construct a 32k16 RAM.
162=32
(3) How many addresses and the data lines are there in a 32k16 RAM.
15 address line
16 data line
(4) What size of the decoder is needed to construct 32k16 memory from the 2k8 chips. What are the inputs to the decoder and where are its outputs connected.
4-16 decoder
地址总线的高 4 位,连接到 16 片芯片的片选信号 - A computer system uses 16-bit memory addresses. It has a 2k-byte cache organized in a direct-mapped manner with 64 bytes per cache block. Assume that the size of each memory word is 1 byte.
(1) Calculate the number of bits in each of the tag, block and word fields of the memory address.
cache 有 64 个 Byte$64=2^{6}$所以需要 6bit 的 word
cache 中可以同时存储2k/64=32 个块,$32=2^{5}$所以需要 5bit 的 block
tag=16-6-5=5bit
如何验算:16bit 的计算机(说到了一个字一个 byte)按照按字寻址应该有$2^{16}$个 Byte,所以有$2^{16-6}=2^{10}$个 block,又已知 cache 中有 32 个块,所以一共有 $2^{10-5}=2^{5}=32$个块会映射到同一个位置,tag 就是用来检查该块是否在 cache 中的,所以这 32 个块都需要有不同的 bit 段,很明显需要 5 个 bit,那么就是 tag=5
(2) When a program is executed, the processor reads data sequentially from the following word addresses: 0080H, 0090H, 0880H, 0884H, 0080H, 0880H. Assume that the cache is initially empty. For each of the above addresses, indicate whether the cache access will result in a hit or a miss.
0000 0000 1000 0000 miss,然后这块索引为 00010 的块都被装入内存
0000 0000 1001 0000 块索引为 00010 在 cache 中,并且对比 tag 位也相同,所以为 hit
0000 1000 1000 0000 块索引为 00010,但 tag 位不同,miss,所以将原来的块进行替换
0000 1000 1000 0100 块索引 00010,tag 位相同 ,hit
0000 0000 1000 0000 块索引在,但是 tag 不同,miss,发生替换
0000 1000 1000 0000 块索引在,tag 不同,miss,发生替换
所以是:
- miss
- hit
- miss
- hit
- miss
- miss




